
Recently have there been astonishing leaps forward within the world of artificial intelligence (AI), particularly when it comes to image generation. Highly revolutionary innovations include Stable Diffusion Architecture, which is an advanced text-to-image model that has completely transformed how we create and manipulate graphics. Stable Diffusion’s capacity to produce realistic images quickly revolutionized fields ranging from fine art to commercial graphic design, advertising, and entertainment.
Understanding Stable Diffusion

Before we can begin to understand the true power of Stable Diffusion, we need to cover some ground, like, what it is, and how does it work? How does it work — and when would a judge or the government be able to use it?
What is Stable Diffusion?
Stable Diffusion is fundamentally a deep learning model made to produce images based on text prompts. It is a tremendous advancement in the generative AI platform that generates realistic visuals using diffusion methods.
- Stable Diffusion is a latent diffusion model (LDM): Diffusion processes at a low resolution and in compressed latent space. Put simply, it turns random noise into coherent, high-quality images that are directed by the user with text input.
- Historical context: Launched by Stability AI in 2022, Stable Diffusion was developed as an extension of previous diffusion models like DALL-E and Imagen. Being open-source, it has democratized the access to state-of-the-art image generation capabilities.
With its wide-ranging applications and cross-platform support, Stable Diffusion witnessed rapid adoption among developers, artists, and researchers alike.
Also read (cuban architecture)
Essential Parts of Stable Diffusion Architecture
Stable Diffusion is made of many advanced ingredients baked into its architecture that comes together to produce amazing results. Let’s break it down:
Variational Autoencoder (VAE)
The VAE serves an important role in Stable Diffusion. The main value here is that it encodes images from the high dimensions to some latent space representation with loss of space dimension and which should hopefully capture the most salient visual features of the image.
- This allows the model to operate on a more compact representation of data, minimizing storage and processing costs.
- The outputs being sharp and realistic is ensured as the VAE encodes the image and decodes it.
U-Net
The core of the denoising process is the U-Net. It starts with a noisy latent representation, and denoises it over time to produce the image.
- It is meant for a functioning architecture that can work on various levels of multi-scale features.
- That enables it to weigh fine details (such as textures) against broader features (such as shapes and structures).
Text Encoder
The text encoder builds the connection between language and visuals. It encodes the input text prompt into embeddings, directing the model on how to condition the image generation process.
- The text encoder in Stable Diffusion is typically a transformer-based model, such as CLIP (Contrastive Language-Image Pretraining).
- This ensures that the created image is very accurate compared to the text entered by the user.
All of them contribute to enabling Stable Diffusion to generate great quality images with impressive precision.
How Stable Diffusion Works

The components are sketched, let’s dive into the workflow of Stable Diffusion. How do we give it a few words and it spits out a beautiful Image? These are handled as part of the diffusion process and the use of latent diffusion models (LDMs) in two stages.
The Diffusion Process
The diffusion process is the core of Stable Diffusion’s functionality. It comprises two main processes: forward diffusion and reverse diffusion.
Forward Diffusion
The model learns to gradually add noise to the latent representation of an image in this step over multiple iterations. This noise is integrated into the image, resulting in a noisy image that is the starting point of the reverse process.
- Forward diffusion aims to turn the image into noise so it cannot be differentiated from noise.
- Which teaches the model to reconstruct the image during reverse diffusion.
Reverse Diffusion
Now that we have the noisy latent representation, we run the reverse process. In this model, based on the U-Net architecture, the noise is removed step-by-step.
- It produces a high-quality image according to the prompt you wanted.
- Using latent space in this model minimizes the amount of data, making this an efficient process.
Latent Diffusion Models (LDMs)
It is a member of the family of latent diffusion models (LDMs) designed to work in a compressed latent space rather than the pixel space. This method has a few benefits:
- Efficiency: The infeasibility of working in pixel space is overcome, as working with latent space requires significantly less memory and processing power, resulting in more rapid and accessible models.
- Scalability: LDMs process larger and more intricate datasets with minimal performance compromise.
Stable Diffusion enables this between the synergy of LDMs to the optimum trade-off between speed, quality, and computational foot-print.
Stable Diffusion Use Applications
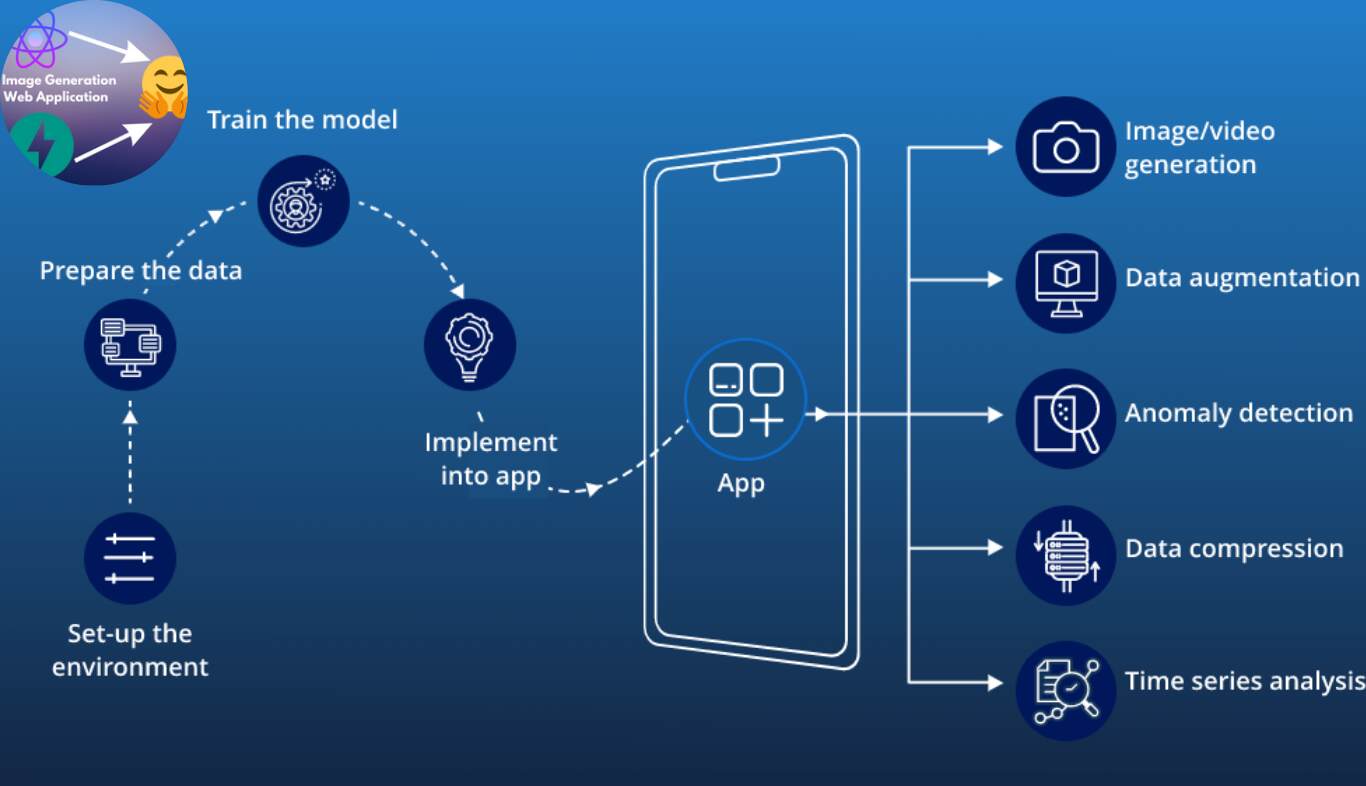
Stable Diffusion’s flexibility has given it a plethora of use cases both artistic and commercial in use. Let’s look at some of its most thrilling uses.
Text-to-Image Generation
A key highlight of Stable Diffusion is its text-to-image capabilities. This has all sorts of applications:
- Art and Illustration: Bypass the limiting feeling of staring at a blank canvas with Stable Diffusion, artists need only describe their ideas for unique visuals to be created.
- Advertising: Marketers can rapidly generate visuals for campaigns specific to a theme or product.
Examples
Type “a futuristic cityscape at sunset,” and then get a vibrant digital painting that matches your exact request. The options for customization are endless!
Providing Task to Image Editing and Manipulation
Aside from creating new images, Stable Diffusion is also great for editing and enhancing current images. Here are two key techniques:
Inpainting and Outpainting
- Inpainting: Filling out missing components of an image (e.g. restoring broken photographs)
- Outpainting: Expand an image beyond its initial limits into a bigger artwork.
Guided Image Synthesis
By blending text prompts into pre-existing images, Stable Diffusion gives users a way to artfully alter visuals. For example, you could use an instruction in text to turn a daytime landscape into a nighttime scene.
How Stable Diffusion Susceptible Data Disfavors You

Stable Diffusion is not only an engineering feat — it is also a potentially transformative tool for creativity, accessibility and innovation in countless industries.
Computational Efficiency
Imagine all of that but instead of training an entire neural network you simply shuffle a few tensors around.
Memory and Time Efficient: Running in latent space with the underlying image encoder significantly reduces the computation, allowing the model to run on consumer GPUs.
Affordability: This enables hobbyists and small businesses to access state-of-the-art AI without the need for costly hardware.
Applications for the Creative and Commercial
Art and Design
Whether it is graphic design, digital art or any other medium, Stable Diffusion gives creators the ability to experiment and build without borders.
Business Applications
Industries such as marketing, advertising, and entertainment are leveraging Stable Diffusion to generate visually appealing content quickly and economically.
| Industry | Application | Benefit |
| Art and Design | Creating custom illustrations | Faster, cost-effective production |
| Marketing | Generating campaign visuals | Tailored and impactful advertisements |
| Entertainment | Concept art and storyboarding | Streamlined pre-production processes |
Issues and Directions for the Future

Though Stable Diffusion is considered revolutionary, it’s not without its challenges. Now let’s explore some limitations and opportunities for improvement.
Limitations and Challenges
Ethical Considerations
The Explosion of AI-Generated Content Is Concerned By Usability, Such As Creating Counterfeit Images Or Violating Copyright Law.
Technical Challenges
While Stable Diffusion is efficient, training still requires a lot of computational resources. It can also produce artifacts or errors in highly detailed images.
Future Developments
Potential Enhancements
This could provide researchers the means to speed up and improve Stable Diffusion even further. Future updates may include:
- Better alignment between texts and images.
- Enhanced detail generation.
Impact on Industries
With the advancements in Stable Diffusion, it is likely that its impact may flow into virtual reality, gaming, and education sectors, transforming them with fields with photorealistic and adaptable imagery.
Also read (1500 square foot house 2 story)